Gini coefficient

The Gini coefficient is a measure of statistical dispersion developed by the Italian statistician Corrado Gini and published in his 1912 paper "Variability and Mutability" (Italian: Variabilità e mutabilità).
The Gini coefficient is a measure of the inequality of a distribution, a value of 0 expressing total equality and a value of 1 maximal inequality. It has found application in the study of inequalities in disciplines as diverse as economics, health science, ecology, chemistry and engineering.
It is commonly used as a measure of inequality of income or wealth. Worldwide, Gini coefficients for income range from approximately 0.23 (Sweden) to 0.70 (Namibia) although not every country has been assessed.
Contents |
Definition

The graph shows that while the Gini is technically equal to the area marked 'A' divided by the sum of the areas marked 'A' and 'B' (that is, Gini = A/(A+B)), it is also equal to 2*A, since A+B = 0.5 since the axes scale from 0 to 1.
The Gini coefficient is usually defined mathematically based on the Lorenz curve, which plots the proportion of the total income of the population (y axis) that is cumulatively earned by the bottom x% of the population (see diagram). The line at 45 degrees thus represents perfect equality of incomes. The Gini coefficient can then be thought of as the ratio of the area that lies between the line of equality and the Lorenz curve (marked 'A' in the diagram) over the total area under the line of equality (marked 'A' and 'B' in the diagram); i.e., G=A/(A+B).
The Gini coefficient can range from 0 to 1; it is sometimes multiplied by 100 to range between 0 and 100. A low Gini coefficient indicates a more equal distribution, with 0 corresponding to complete equality, while higher Gini coefficients indicate more unequal distribution, with 1 corresponding to complete inequality. To be validly computed, no negative goods can be distributed. Thus, if the Gini coefficient is being used to describe household income inequality, then no household can have a negative income. When used as a measure of income inequality, the most unequal society will be one in which a single person receives 100% of the total income and the remaining people receive none (G=1); and the most equal society will be one in which every person receives the same percentage of the total income (G=0).
Some find it more intuitive (and it is mathematically equivalent) to think of the Gini coefficient as half of the Relative mean difference. The mean difference is the average absolute difference between two items selected randomly from a population, and the relative mean difference is the mean difference divided by the average, to normalize for scale.
Calculation
The Gini index is defined as a ratio of the areas on the Lorenz curve diagram. If the area between the line of perfect equality and the Lorenz curve is A, and the area under the Lorenz curve is B, then the Gini index is A/(A+B). Since A+B = 0.5, the Gini index, G = A/(0.5) = 2A = 1-2B. If the Lorenz curve is represented by the function Y = L(X), the value of B can be found with integration and:
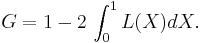
In some cases, this equation can be applied to calculate the Gini coefficient without direct reference to the Lorenz curve. For example:
- For a population uniform on the values yi, i = 1 to n, indexed in non-decreasing order ( yi ≤ yi+1):
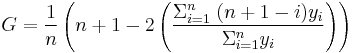
- This may be simplified to:
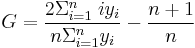
- For a discrete probability function f(y), where yi, i = 1 to n, are the points with nonzero probabilities and which are indexed in increasing order ( yi < yi+1):
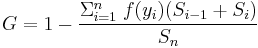
- where
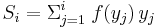 and
and 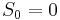
- For a cumulative distribution function F(y) that is piecewise differentiable, has a mean μ, and is zero for all negative values of y:
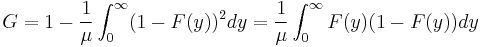
- Since the Gini coefficient is half the relative mean difference, it can also be calculated using formulas for the relative mean difference. For a random sample S consisting of values yi, i = 1 to n, that are indexed in non-decreasing order ( yi ≤ yi+1), the statistic:

- is a consistent estimator of the population Gini coefficient, but is not, in general, unbiased. Like, G, G(S) has a simpler form:
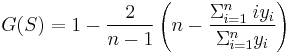 .
.
There does not exist a sample statistic that is in general an unbiased estimator of the population Gini coefficient, like the relative mean difference.
Sometimes the entire Lorenz curve is not known, and only values at certain intervals are given. In that case, the Gini coefficient can be approximated by using various techniques for interpolating the missing values of the Lorenz curve. If ( X k , Yk ) are the known points on the Lorenz curve, with the X k indexed in increasing order ( X k - 1 < X k ), so that:
- Xk is the cumulated proportion of the population variable, for k = 0,...,n, with X0 = 0, Xn = 1.
- Yk is the cumulated proportion of the income variable, for k = 0,...,n, with Y0 = 0, Yn = 1.
If the Lorenz curve is approximated on each interval as a line between consecutive points, then the area B can be approximated with trapezoids and:
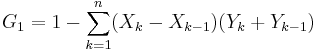
is the resulting approximation for G. More accurate results can be obtained using other methods to approximate the area B, such as approximating the Lorenz curve with a quadratic function across pairs of intervals, or building an appropriately smooth approximation to the underlying distribution function that matches the known data. If the population mean and boundary values for each interval are also known, these can also often be used to improve the accuracy of the approximation.
The Gini coefficient calculated from a sample is a statistic and its standard error, or confidence intervals for the population Gini coefficient, should be reported. These can be calculated using bootstrap techniques but those proposed have been mathematically complicated and computationally onerous even in an era of fast computers. Ogwang (2000) made the process more efficient by setting up a “trick regression model” in which the incomes in the sample are ranked with the lowest income being allocated rank 1. The model then expresses the rank (dependent variable) as the sum of a constant A and a normal error term whose variance is inversely proportional to yk;
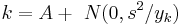
Ogwang showed that G can be expressed as a function of the weighted least squares estimate of the constant A and that this can be used to speed up the calculation of the jackknife estimate for the standard error. Giles (2004) argued that the standard error of the estimate of A can be used to derive that of the estimate of G directly without using a jackknife at all. This method only requires the use of ordinary least squares regression after ordering the sample data. The results compare favorably with the estimates from the jackknife with agreement improving with increasing sample size. The paper describing this method can be found here: http://web.uvic.ca/econ/ewp0202.pdf
However it has since been argued that this is dependent on the model’s assumptions about the error distributions (Ogwang 2004) and the independence of error terms (Reza & Gastwirth 2006) and that these assumptions are often not valid for real data sets. It may therefore be better to stick with jackknife methods such as those proposed by Yitzhaki (1991) and Karagiannis and Kovacevic (2000). The debate continues.
The Gini coefficient can be calculated if you know the mean of a distribution, the number of people (or percentiles), and the income of each person (or percentile). Princeton development economist Angus Deaton (1997, 139) simplified the Gini calculation to one easy formula:
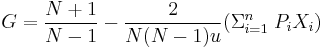
where u is mean income of the population, Pi is the income rank P of person i, with income X, such that the richest person receives a rank of 1 and the poorest a rank of N. This effectively gives higher weight to poorer people in the income distribution, which allows the Gini to meet the Transfer Principle.
Generalised inequality index
The Gini coefficient and other standard inequality indices reduce to a common form. Perfect equality—the absence of inequality—exists when and only when the inequality ratio, 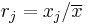 , equals 1 for all j units in some population; for example, there is perfect income equality when everyone’s income
, equals 1 for all j units in some population; for example, there is perfect income equality when everyone’s income 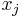 equals the mean income
equals the mean income  , so that
, so that 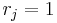 for everyone). Measures of inequality, then, are measures of the average deviations of the from 1; the greater the average deviation, the greater the inequality. Based on these observations the inequality indices have this common form:[1]
for everyone). Measures of inequality, then, are measures of the average deviations of the from 1; the greater the average deviation, the greater the inequality. Based on these observations the inequality indices have this common form:[1]
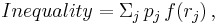
where pj weights the units by their population share, and f(rj) is a function of the deviation of each unit’s rj from 1, the point of equality. The insight of this generalised inequality index is that inequality indices differ because they employ different functions of the distance of the inequality ratios (the rj) from 1.
Gini coefficient of income distributions
While developed European nations and Canada tend to have Gini indices between 24 and 36, the United States' and Mexico's Gini indices are both above 40, indicating that the United States and Mexico have greater inequality. Using the Gini can help quantify differences in welfare and compensation policies and philosophies. However it should be borne in mind that the Gini coefficient can be misleading when used to make political comparisons between large and small countries (see criticisms section).
The Gini index for the entire world has been estimated by various parties to be between 56 and 66.[2][3]
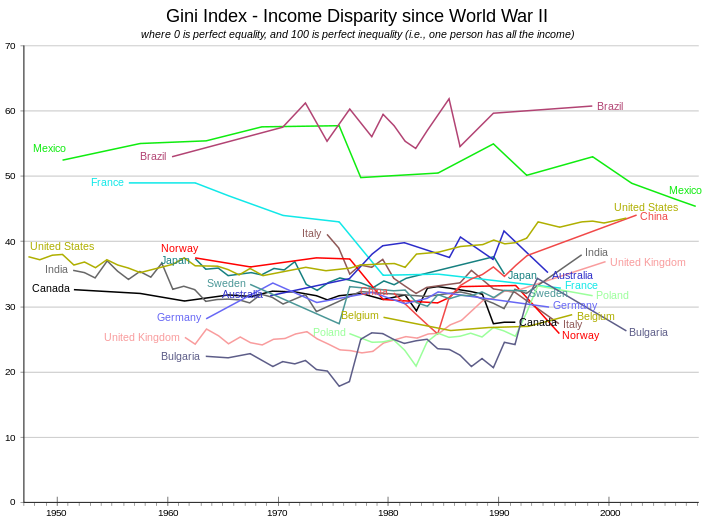
US income Gini indices over time
Gini indices for the United States at various times, according to the US Census Bureau:[4][5]
- 1929: 45.0 (estimated)
- 1947: 37.6 (estimated)
- 1967: 39.7 (first year reported)
- 1968: 38.6 (lowest index reported)
- 1970: 39.4
- 1980: 40.3
- 1990: 42.8
- 2000: 46.2 [6]
- 2005: 46.9
- 2006: 47.0 (highest index reported)
- 2007: 46.3
- 2008: 46.69
EU Gini index
In 2005 the AVERAGE Gini index for the EU was estimated at 31.[7]
Advantages of Gini coefficient as a measure of inequality
- The Gini coefficient's main advantage is that it is a measure of inequality by means of a ratio analysis, rather than a variable unrepresentative of most of the population, such as per capita income or gross domestic product.
- It can be used to compare income distributions across different population sectors as well as countries, for example the Gini coefficient for urban areas differs from that of rural areas in many countries (though the United States' urban and rural Gini coefficients are nearly identical).
- It is sufficiently simple that it can be compared across countries and be easily interpreted. GDP statistics are often criticized as they do not represent changes for the whole population; the Gini coefficient demonstrates how income has changed for poor and rich. If the Gini coefficient is rising as well as GDP, poverty may not be improving for the majority of the population.
- The Gini coefficient can be used to indicate how the distribution of income has changed within a country over a period of time, thus it is possible to see if inequality is increasing or decreasing.
- The Gini coefficient satisfies four important principles[8]:
- Anonymity: it does not matter who the high and low earners are.
- Scale independence: the Gini coefficient does not consider the size of the economy, the way it is measured, or whether it is a rich or poor country on average.
- Population independence: it does not matter how large the population of the country is.
- Transfer principle: if income (less than half of the difference), is transferred from a rich person to a poor person the resulting distribution is more equal.
Disadvantages of Gini coefficient as a measure of inequality
- While the Gini coefficient measures inequality of income, it does not measure inequality of opportunity. For example, the United Kingdom has a social class structure that may present barriers to upward mobility; this is not reflected in its Gini coefficient.
- The Gini coefficient of different sets of people cannot be averaged to obtain the Gini coefficient of all the people in the sets: if a Gini coefficient were to be calculated for each person it would always be zero. For a large, economically diverse country, a much higher coefficient will be calculated for the country as a whole than will be calculated for each of its regions. (The coefficient is usually applied to measurable nominal income rather than local purchasing power, tending to increase the calculated coefficient across larger areas.)
- The Lorenz curve may understate the actual amount of inequality if richer households are able to use income more efficiently than lower income households or vice versa. From another point of view, measured inequality may be the result of more or less efficient use of household incomes.
- Economies with similar incomes and Gini coefficients can still have very different income distributions. This is because the Lorenz curves can have different shapes and yet still yield the same Gini coefficient. For example, consider a society where half of individuals had no income and the other half shared all the income equally (i.e. whose Lorenz curve is linear from (0,0) to (0.5,0) and then linear to (1,1)). As is easily calculated, this society has Gini coefficient 0.5 -- the same as that of a society in which 75% of people equally shared 25% of income while the remaining 25% equally shared 75% (i.e. whose Lorenz curve is linear from (0,0) to (0.75,0.25) and then linear to (1,1)).
- It measures current income rather than lifetime income. A society in which everyone earned the same over a lifetime would appear unequal because of people at different stages in their life; a society in which students study rather than save can never have a coefficient of 0. However, Gini coefficient can also be calculated for any kind of distribution, e.g. for wealth.[9]
- Gini coefficients do include investment income; however, the Gini coefficient based on net income does not accurately reflect differences in wealth—a possible source of misinterpretation. For example, Sweden has a low Gini coefficient for income distribution but a significantly higher Gini coefficient for wealth (for instance 77% of the share value owned by households is held by just 5% of Swedish shareholding households )[10]. In other words, the Gini income coefficient should not be interpreted as measuring effective egalitarianism.
- Too often only the Gini coefficient is quoted without describing the proportions of the quantiles used for measurement. As with other inequality coefficients, the Gini coefficient is influenced by the granularity of the measurements. For example, five 20% quantiles (low granularity) will usually yield a lower Gini coefficient than twenty 5% quantiles (high granularity) taken from the same distribution. This is an often encountered problem with measurements.
- Care should be taken in using the Gini coefficient as a measure of egalitarianism, as it is properly a measure of income dispersion. For example, if two equally egalitarian countries pursue different immigration policies, the country accepting higher proportion of low-income or impoverished migrants will be assessed as less equal (gain a higher Gini coefficient).
- The Gini coefficient is a point-estimate of equality at a certain time, hence it ignores life-span changes in income. Typically, increases in the proportion of young or old members of a society will drive apparent changes in equality. Because of this, factors such as age distribution within a population and mobility within income classes can create the appearance of differential equality when none exist taking into account demographic effects. Thus a given economy may have a higher Gini coefficient at any one point in time compared to another, while the Gini coefficient calculated over individuals' lifetime income is actually lower than the apparently more equal (at a given point in time) economy's.[11] Essentially, what matters is not just inequality in any particular year, but the composition of the distribution over time.
General problems of measurement
- Comparing income distributions among countries may be difficult because benefits systems may differ. For example, some countries give benefits in the form of money while others give food stamps, which might not be counted by some economists and researchers as income in the Lorenz curve and therefore not taken into account in the Gini coefficient. Income in the United States is counted before benefits, while in France it is counted after benefits, which may lead the United States to appear somewhat more unequal vis-a-vis France. In another example, the Soviet Union was measured to have relatively high income inequality: by some estimates, in the late 1970s, Gini coefficient of its urban population was as high as 0.38,[12] which is higher than many Western countries today. This number would not reflect those benefits received by Soviet citizens that were not monetized for measurement, which may include child care for children as young as two months, elementary, secondary and higher education, cradle-to-grave medical care, and heavily subsidized or provided housing. In this example, a more accurate comparison between the 1970s Soviet Union and Western countries may require one to assign monetary values to all benefits – a difficult task in the absence of free markets. Similar problems arise whenever a comparison between pure free-market economies and partially socialist economies is attempted. Benefits may take various and unexpected forms: for example, major oil producers such as Venezuela and Iran provide indirect benefits to its citizens by subsidizing the retail price of gasoline.
- Similarly, in some societies people may have significant income in other forms than money, for example through subsistence farming or bartering. Like non-monetary benefits, the value of these incomes is difficult to quantify. Different quantifications of these incomes will yield different Gini coefficients.
- The measure will give different results when applied to individuals instead of households. When different populations are not measured with consistent definitions, comparison is not meaningful.
- As for all statistics, there may be systematic and random errors in the data. The meaning of the Gini coefficient decreases as the data become less accurate. Also, countries may collect data differently, making it difficult to compare statistics between countries.
As one result of this criticism, in addition to or in competition with the Gini coefficient entropy measures are frequently used (e.g. the Theil Index and the Atkinson index). These measures attempt to compare the distribution of resources by intelligent agents in the market with a maximum entropy random distribution, which would occur if these agents acted like non-intelligent particles in a closed system following the laws of statistical physics.
Credit risk
The Gini coefficient is also commonly used for the measurement of the discriminatory power of rating systems in credit risk management.
The discriminatory power refers to a credit risk model's ability to differentiate between defaulting and non-defaulting clients. The above formula  may be used for the final model and also at individual model factor level, to quantify the discriminatory power of individual factors. This is as a result of too many non defaulting clients falling into the lower points scale e.g. factor has a 10 point scale and 30% of non defaulting clients are being assigned the lowest points available e.g. 0 or negative points. This indicates that the factor is behaving in a counter-intuitive manner and would require further investigation at the model development stage. [13]
may be used for the final model and also at individual model factor level, to quantify the discriminatory power of individual factors. This is as a result of too many non defaulting clients falling into the lower points scale e.g. factor has a 10 point scale and 30% of non defaulting clients are being assigned the lowest points available e.g. 0 or negative points. This indicates that the factor is behaving in a counter-intuitive manner and would require further investigation at the model development stage. [13]
Other uses
Although the Gini coefficient is most popular in economics, it can in theory be applied in any field of science that studies a distribution. For example, in ecology the Gini coefficient has been used as a measure of biodiversity, where the cumulative proportion of species is plotted against cumulative proportion of individuals.[14] In health, it has been used as a measure of the inequality of health related quality of life in a population.[15] In education, it has been used as a measure of the inequality of universities.[16] In chemistry it has been used to express the selectivity of protein kinase inhibitors against a panel of kinases.[17] In engineering, it has been used to evaluate the fairness achieved by Internet routers in scheduling packet transmissions from different flows of traffic.[18] In statistics, building decision trees, it is used to measure the purity of possible child nodes, with the aim of maximising the average purity of two child nodes when splitting.
See also
|
|
|
References
- ↑ Firebaugh, Glenn (1999). "Empirics of World Income Inequality". American Journal of Sociology 104 (6): 1597–1630. doi:10.1086/210218. See also
- ↑ Bob Sutcliffe (April 2007). "Postscript to the article ‘World inequality and globalization’ (Oxford Review of Economic Policy, Spring 2004)". http://siteresources.worldbank.org/INTDECINEQ/Resources/PSBSutcliffe.pdf. Retrieved 2007-12-13
- ↑ United Nations Development Programme
- ↑ "Gini Ratios for Households, by Race and Hispanic Origin of Householder: 1967 to 2007". Historical Income Tables - Households. United States Census Bureau. http://www.census.gov/hhes/www/income/histinc/h04.html.
- ↑ "Table 3. Income Distribution Measures Using Money Income and Equivalence-Adjusted Income: 2007 and 2008". Income, Poverty, and Health Insurance Coverage in the United States: 2008. United States Census Bureau. p. 17. http://www.census.gov/prod/2009pubs/p60-236.pdf.
- ↑ Note that the calculation of the index for the United States was changed in 1992, resulting in an upwards shift of about 2.
- ↑ "Monitoring quality of life in Europe - Gini index". Eurofound. 26 August 2009. http://www.eurofound.europa.eu/areas/qualityoflife/eurlife/index.php?template=3&radioindic=158&idDomain=3.
- ↑ Ray, Debraj (1998). Development Economics. Princeton, NJ: Princeton University Press. p. 188. ISBN 0691017069.
- ↑ Friedman, David D.
- ↑ (Data from the Statistics Sweden.)
- ↑ Blomquist, N. (1981). "A comparison of distributions of annual and lifetime income: Sweden around 1970". Review of Income and Wealth 27 (3): 243–264. doi:10.1111/j.1475-4991.1981.tb00227.x.
- ↑ Millar, James R. (1987). Politics, work, and daily life in the USSR. New York: Cambridge University Press. p. 193. ISBN 0521348900.
- ↑ The Analytics of risk model validation
- ↑ Wittebolle, Lieven; et al. (2009). "Initial community evenness favours functionality under selective stress". Nature 458 (7238): pp. 623–626. doi:10.1038/nature07840.
- ↑ Asada, Yukiko (2005). "Assessment of the health of Americans: the average health-related quality of life and its inequality across individuals and groups". Population Health Metrics 3: pp. 7. doi:10.1186/1478-7954-3-7.
- ↑ Halffman, Willem (2010). "Is Inequality Among Universities Increasing? Gini Coefficients and the Elusive Rise of Elite Universities". Minerva 48: pp. 55–72. doi:10.1007/s11024-010-9141-3.
- ↑ Graczyk, Piotr (2007). "Gini Coefficient: A New Way To Express Selectivity of Kinase Inhibitors against a Family of Kinases". Journal of Medicinal Chemistry 50: pp. 5773–5779. doi:10.1021/jm070562u.
- ↑ Shi, Hongyuan; Sethu, Harish (2003). "Greedy Fair Queueing: A Goal-Oriented Strategy for Fair Real-Time Packet Scheduling". Proceedings of the 24th IEEE Real-Time Systems Symposium. IEEE Computer Society. pp. 345–356. ISBN 0-7695-2044-8
Further reading
- Amiel, Y.; Cowell, F.A. (1999). Thinking about Inequality. Cambridge.
- Anand, Sudhir (1983). Inequality and Poverty in Malaysia. New York: Oxford University Press.
- Brown, Malcolm (1994). "Using Gini-Style Indices to Evaluate the Spatial Patterns of Health Practitioners: Theoretical Considerations and an Application Based on Alberta Data". Social Science Medicine 38 (9): 1243–1256. doi:10.1016/0277-9536(94)90189-9. PMID 8016689.
- Chakravarty, S. R. (1990). Ethical Social Index Numbers. New York: Springer-Verlag.
- Deaton, Angus (1997). Analysis of Household Surveys. Baltimore MD: Johns Hopkins University Press.
- Dixon, PM, Weiner J., Mitchell-Olds T, Woodley R. (1987). "Bootstrapping the Gini coefficient of inequality". Ecology (Ecological Society of America) 68 (5): 1548–1551. doi:10.2307/1939238. http://jstor.org/stable/1939238.
- Dorfman, Robert (1979). "A Formula for the Gini Coefficient". The Review of Economics and Statistics (The MIT Press) 61 (1): 146–149. doi:10.2307/1924845. http://jstor.org/stable/1924845.
- Firebaugh, Glenn (2003). The New Geography of Global Income Inequality. Cambridge MA: Harvard University Press.
- Gastwirth, Joseph L. (1972). "The Estimation of the Lorenz Curve and Gini Index". The Review of Economics and Statistics (The MIT Press) 54 (3): 306–316. doi:10.2307/1937992. http://jstor.org/stable/1937992.
- Giles, David (2004). "Calculating a Standard Error for the Gini Coefficient: Some Further Results". Oxford Bulletin of Economics and Statistics 66: 425–433. doi:10.1111/j.1468-0084.2004.00086.x.
- Gini, Corrado (1912). "Variabilità e mutabilità" Reprinted in Memorie di metodologica statistica (Ed. Pizetti E, Salvemini, T). Rome: Libreria Eredi Virgilio Veschi (1955).
- Gini, Corrado (1921). "Measurement of Inequality of Incomes". The Economic Journal (Blackwell Publishing) 31 (121): 124–126. doi:10.2307/2223319. http://jstor.org/stable/2223319.
- Karagiannis, E. and Kovacevic, M. (2000). "A Method to Calculate the Jackknife Variance Estimator for the Gini Coefficient". Oxford Bulletin of Economics and Statistics 62: 119–122. doi:10.1111/1468-0084.00163.
- Mills, Jeffrey A.; Zandvakili, Sourushe (1997). "Statistical Inference via Bootstrapping for Measures of Inequality". Journal of Applied Econometrics 12: 133–150. doi:10.1002/(SICI)1099-1255(199703)12:2<133::AID-JAE433>3.0.CO;2-H.
- Modarres, Reza and Gastwirth, Joseph L. (2006). "A Cautionary Note on Estimating the Standard Error of the Gini Index of Inequality". Oxford Bulletin of Economics and Statistics 68: 385–390. doi:10.1111/j.1468-0084.2006.00167.x.
- Morgan, James (1962). "The Anatomy of Income Distribution". The Review of Economics and Statistics (The MIT Press) 44 (3): 270–283. doi:10.2307/1926398. http://jstor.org/stable/1926398.
- Ogwang, Tomson (2000). "A Convenient Method of Computing the Gini Index and its Standard Error". Oxford Bulletin of Economics and Statistics 62: 123–129. doi:10.1111/1468-0084.00164.
- Ogwang, Tomson (2004). "Calculating a Standard Error for the Gini Coefficient: Some Further Results: Reply". Oxford Bulletin of Economics and Statistics 66: 435–437. doi:10.1111/j.1468-0084.2004.00087.x.
- Xu, Kuan (January 2004). How Has the Literature on Gini's Index Evolved in the Past 80 Years?. Department of Economics, Dalhousie University. http://economics.dal.ca/RePEc/dal/wparch/howgini.pdf. Retrieved 2006-06-01. The Chinese version of this paper appears in Xu, Kuan (2003). "How Has the Literature on Gini's Index Evolved in the Past 80 Years?". China Economic Quarterly 2: 757–778.
- Yitzhaki, S. (1991). "Calculating Jackknife Variance Estimators for Parameters of the Gini Method". Journal of Business and Economic Statistics (American Statistical Association) 9 (2): 235–239. doi:10.2307/1391792. http://jstor.org/stable/1391792.
External links
- Deutsche Bundesbank: Do banks diversify loan portfolios?, 2005 (on using e.g. the Gini coefficient for risc evaluation of loan portefolios)
- Forbes Article, In praise of inequality
- Measuring Software Project Risk With The Gini Coefficient, an application of the Gini coefficient to software
- The World Bank: Measuring Inequality
- Travis Hale, University of Texas Inequality Project:The Theoretical Basics of Popular Inequality Measures, online computation of examples: 1A, 1B
- United States Census Bureau List of Gini Coefficients by State for Families and Households
- Article from The Guardian analysing inequality in the UK 1974 - 2006
- World Income Inequality Database
- Income Distribution and Poverty in OECD Countries
- Software:
- A Matlab Inequality Package, including code for computing Gini, Atkinson, Theil indexes and for plotting the Lorenz Curve. Many examples are available.
- Free Online Calculator computes the Gini Coefficient, plots the Lorenz curve, and computes many other measures of concentration for any dataset
- Free Calculator: Online and downloadable scripts (Python and Lua) for Atkinson, Gini, and Hoover inequalities
- Users of the R data analysis software can install the "ineq" package which allows for computation of a variety of inequality indices including Gini, Atkinson, Theil.